В сообществе пользователей предпочитающих запуск ИИ на свем компе с помощью локальных моделей всё чаще обсуждается технология Multi-Token Prediction (MTP). Рассмотрим запуск популярной модели Qwen 3.6 27p с помощью этой технологии на видеокарте RTX 3090 24 Gb. Пока в основной ветке llama.cpp ожидается слияние (merge) соответствующих изменений, энтузиасты уже нашли способ использовать эту технологию через форки. В этой статье мы разберем, что такое MTP, чем она отличается от классического спекулятивного декодирования (D Flash) и как запустить её на собственном железе.
Что такое Multi-Token Prediction?
В стандартном режиме инференса (авторегрессионном) модель работает по принципу «один проход — один токен». Чтобы сгенерировать следующее слово, модель должна заново прогнать весь контекст через все свои слои.
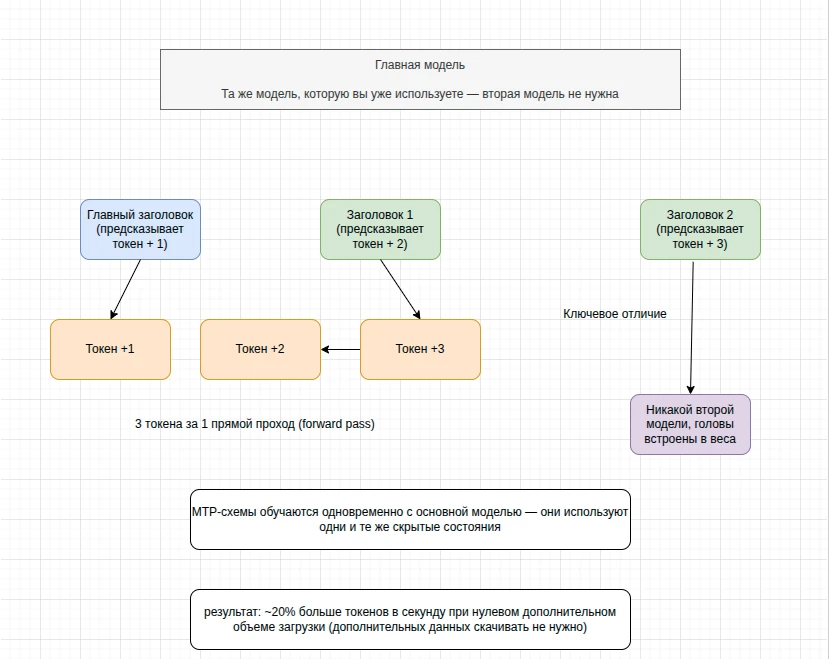
MTP (Multi-Token Prediction) меняет этот подход на этапе архитектуры обучения. Вместо одной схемы предсказания (prediction head) в модель встраиваются дополнительные схемы.
Как это работает:
- Во время одного прямого прохода (forward pass) через нейросеть, основная схема предсказывает текущий токен ($T$).
- Дополнительные MTP-схемы, используя те же скрытые состояния (hidden states), предсказывают следующие токены ($T+1, T+2$ и т.д.).
- В результате за одну итерацию вы получаете сразу несколько токенов без необходимости запускать отдельную модель или дополнительный процесс.
Это преимущество «зашито» непосредственно в веса модели, что делает процесс максимально эффективным.
Сравнение: MTP vs. DFlash (Speculative Decoding)
Часто MTP путают с классическим спекулятивным декодированием (например, технологией DFlash). Разница заключается в архитектуре и сложности настройки.
| Характеристика | Multi-Token Prediction (MTP) | DFlash (Speculative Decoding) |
|---|---|---|
| Архитектура | Одна модель с несколькими «схемами» | Две модели (малая «draft» + большая основная) |
| Скорость | Умеренный прирост (~20%) | Высокий прирост (~300%) |
| Сложность | Низкая (один GGUF файл) | Высокая (нужно две модели и кастомный runtime) |
| Ресурсы | Минимальное потребление VRAM | Значительное потребление VRAM |
Резюме: MTP — это идеальное решение, когда нужна максимальная простота и минимальные затраты ресурсов, в то время как DFlash лучше подходит для задач, где критична максимальная пропускная способность.
Практическая реализация с использованием ik_llama.cpp
Поскольку поддержка MTP еще не добавлена в mainline llama.cpp, мы будем использовать форк ik_llama.cpp, который уже оптимизирован под эту задачу.
Шаг 1: Сборка движка
Сначала необходимо клонировать репозиторий и собрать проект:
git clone https://github.com/ikawrakow/ik_llama.cpp.git
cd ik_llama.cpp
Внимание! У вас должен быть установлен cmake для сборки проекта. Я запускаю процесс скачивания и сбоки проекта при помощи следующего bash скрипта:
#!/bin/bash
set -e
# install_ik_llama_cpp.sh
# --------------------
# Installs prerequisites and builds ikawrakow/ik_llama on Linux.
# Mimics the functionality of install_llama_cpp.ps1
# Helper to check commands
command_exists() {
command -v "$1" >/dev/null 2>&1
}
echo "Checking prerequisites..."
if ! command_exists git; then
echo "Error: 'git' is not installed. Please install it using your package manager."
exit 1
fi
if ! command_exists cmake; then
echo "Error: 'cmake' is not installed. Please install it using your package manager."
exit 1
fi
if ! command_exists node; then
echo "Error: 'node' (Node.js) is not installed. Please install it (LTS version recommended)."
exit 1
fi
if ! command_exists npm; then
echo "Error: 'npm' is not installed. Please install it."
exit 1
fi
if ! command_exists ninja; then
echo "Warning: 'ninja' is not installed. CMake will default to 'make'."
echo " Installing ninja-build is recommended for faster builds."
fi
if ! command_exists nvcc; then
echo "Warning: 'nvcc' (CUDA compiler) not found in PATH."
echo " Build will likely fall back to CPU-only or fail if CUDA is expected."
echo " Please ensure the CUDA Toolkit (12.4+) is installed and in your PATH."
else
NVCC_VERSION=$(nvcc --version | grep "release" | sed 's/.*release //;s/,.*//')
echo "Found CUDA compiler: $NVCC_VERSION"
fi
# Setup directories
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )"
LLAMA_REPO="$SCRIPT_DIR/ik_llama.cpp"
LLAMA_BUILD="$LLAMA_REPO/build"
# Clone or Update llama.cpp
if [ ! -d "$LLAMA_REPO" ]; then
echo "-> Cloning ik_llama.cpp into $LLAMA_REPO..."
git clone https://github.com/ikawrakow/ik_llama.cpp "$LLAMA_REPO"
else
echo "-> Updating existing ik_llama.cpp in $LLAMA_REPO..."
git -C "$LLAMA_REPO" pull --ff-only
fi
git -C "$LLAMA_REPO" submodule update --init --recursive
# Configure & Build
echo "-> Configuring CMake..."
mkdir -p "$LLAMA_BUILD"
cd "$LLAMA_BUILD"
# CMake Arguments
# -DGGML_CUDA=ON enables CUDA backend
# -DCMAKE_CUDA_ARCHITECTURES=native targets the local GPU
CMAKE_ARGS="-DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release -DLLAMA_CURL=OFF -DGGML_CUDA_FA_ALL_QUANTS=ON -DCMAKE_CUDA_ARCHITECTURES=native"
if command_exists ninja; then
CMAKE_ARGS="-G Ninja $CMAKE_ARGS"
fi
echo "Running cmake with: $CMAKE_ARGS"
cmake .. $CMAKE_ARGS
echo "-> Building targets (llama-server, llama-cli, etc.)..."
cmake --build . --config Release --target llama-server llama-batched-bench llama-cli llama-bench --parallel
echo ""
echo "Done! ik_llama.cpp (CUDA) binaries are in: $LLAMA_BUILD/bin"
Шаг 2: Параметры запуска
Для работы с MTP критически важны специфические флаги командной строки. Рассмотрим основные:
--mtp: Включает поддержку мультитокенного предсказания.--draft-max [N]: Указывает количество дополнительных токенов, которые MTP-головы будут пытаться предсказать за один шаг. Примечание: для моделей типа Qwen оптимальным значением является1.--draft-p-min [0]: Устанавливает порог принятия предсказанных токенов. Значение0означает, что мы принимаем все предсказания без учета их вероятности (не отклоняем токены).
Бенчмарк: Тестирование производительности
Для проверки эффективности был проведен тест на системе с GPU NVIDIA RTX 3090 (24GB VRAM) с использованием модели на базе Qwen в формате GGUF.
Конфигурация теста:
- Модель: Qwen-based GGUF (~16 ГБ)
- Hardware: Arch linux, RTX 3090
- Метод: Сравнение чистого авторегрессионного инференса и инференса с включенным MTP.
Результаты:
| Режим работы | Скорость (Tokens/sec) | Прирост производительности |
|---|---|---|
| Baseline (Без MTP) | 34.2 t/s | — |
| MTP Enabled | 41.0 t/s | +20% |
Анализ результатов: Прирост скорости составил ровно 20%, что полностью соответствует теоретическим показателям, заявленным в документации к модели. При этом потребление видеопамяти (VRAM) увеличилось незначительно, в основном за счет расширения KV-кеша.
Заключение
Технология Multi-Token Prediction представляет собой «бесплатный» способ ускорения локальных моделей без потери качества генерации и усложнения инфраструктуры. Если ваша задача не требует экстремальных скоростей, которые дает спекулятивное декодирование, MTP является наиболее сбалансированным выбором для оптимизации инференса.